In the past, when we wanted to store more data or increase our processing power, the common option was to scale vertically (add machines) or further optimise the existing code base. However, with the advances in parallel processing and distributed systems, it is more common to expand horizontally, or have more machines to do the same task in parallel.
Horizontal scaling is performed with help of some tools eg spark ,kafka . It’s works according to CAP theorem.
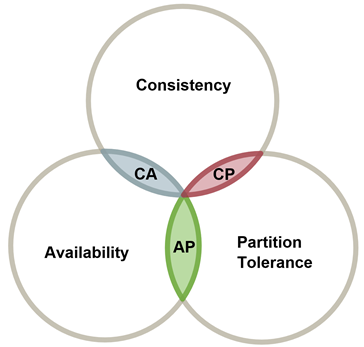
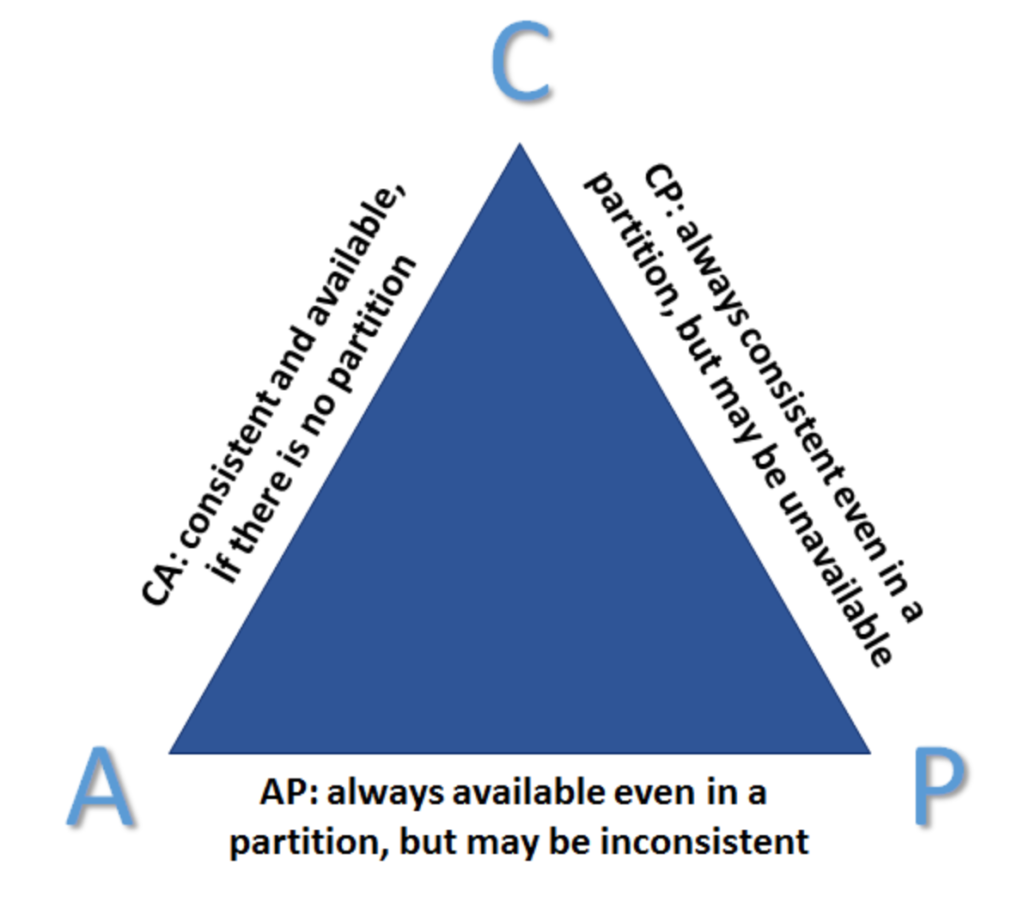
The CAP (Consistency, Availability, Partition Tolerance) theorem states that in the presence of a network partition, which occurs very infrequently, you must choose between consistency, in which every read receives the most recent write or an error, and availability, in which every request receives a non-error response without guarantee of the most recent write.
The PACELC theorem further extends this idea to say that for everything else (E) that happens when there are no network partitions, one must choose between latency (L) and consistency (C).
In a nutshell, these theorems mean there’s a give and take between data consistency, data availability, throughput and latency in a distributed system which directly affects your app user’s experience.
That being said Cosmos DB offers 5 consistency models to cover the spectrum. Sometimes are applications may need to must up to date data. In that case consistency is much more important. Other times our applications may not need the most up to date data. In that case consistency is not as important. The choices below allow us to configure Cosmos DB to consistency needs of our application.
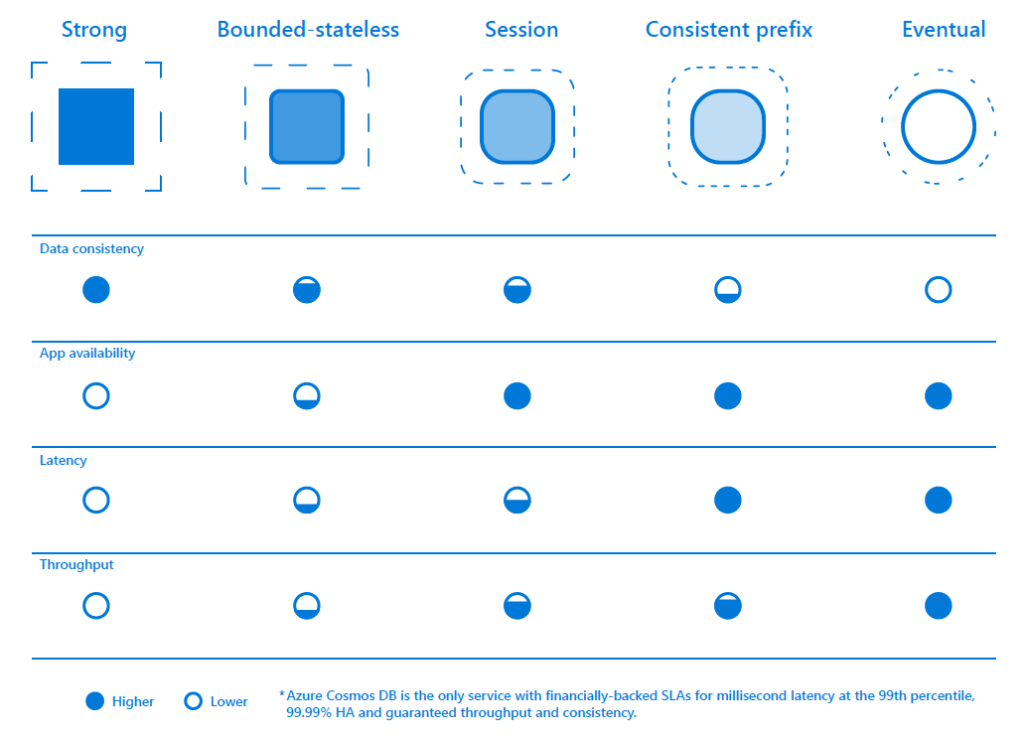
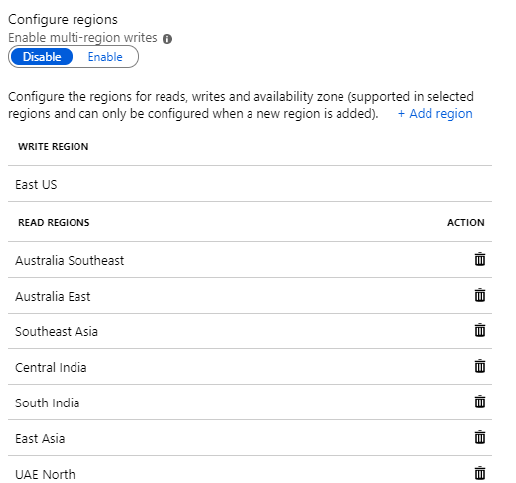
Azure Cosmos DB provide Turn Key Global Distribution Feature to maintain consistency and availability of data.
Associate any
number of regions with your Cosmos DB account
Limited to geo-fencing policies
Dynamically
add/remove region
Associate (and disassociate) regions with the click of a mouse
Multi-master
Enable writes across all regions, with automatic failover
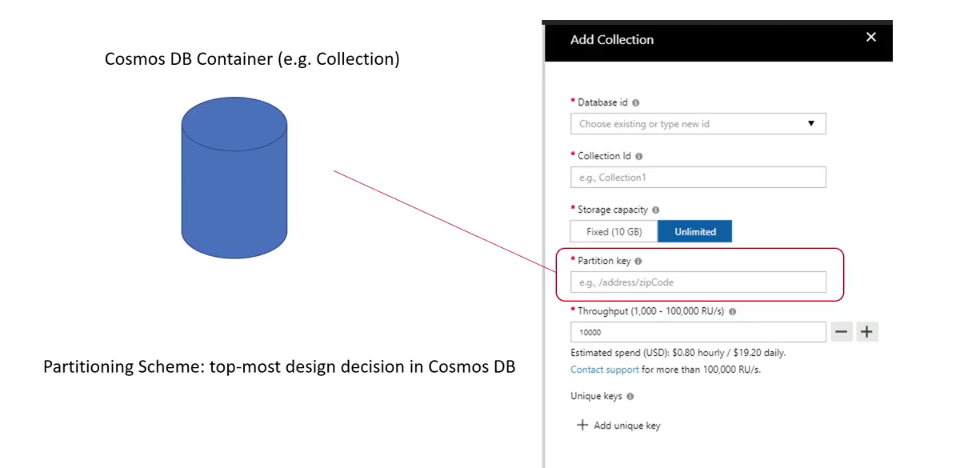
Partitioning
Partitioning is what allows you to massively scale your database, and not just in terms of storage, but also throughput. We can create a container and that cosmos db partitioned the data that you store in that container to manage its growth. This means that you just work with the one container as a single logical resource where you store your data and you can just let the container grow and grow without worrying about scale. Because cosmos Db creates is many partitions as needed. Behind the scenes to accommodate your data. These partitions themselves are the physical storage for the data in your container.
Great content! Super high-quality! Keep it up! 🙂